ChatGPT很强,但它不是万能。这篇文章用通俗语言讲清楚:RAG到底是什么、为什么它才是企业真正需要的AI技术,适合每一个想搞懂AI落地逻辑的人看看。runway

RAG(Retrieval-Augmented Generation,检索增强生成)豆包ai赚钱
我们来详细拆解一下 RAG (检索增强生成) 的工作流程。这是一个将信息检索(IR) 与大语言模型(LLM) 的强大生成能力相结合的过程。ai获客
其核心思想怎么安装豆包是:不要让LLM凭空想象,而是让它基于提供的“参考资料”来回答问题。
整个工作流程可以清晰地划分为两个主要阶段:索引问天ai下载(Indexing) 和查询玻尔学术ai(Retrieval & Generation)。下图展示了这一过程的完整蓝图:
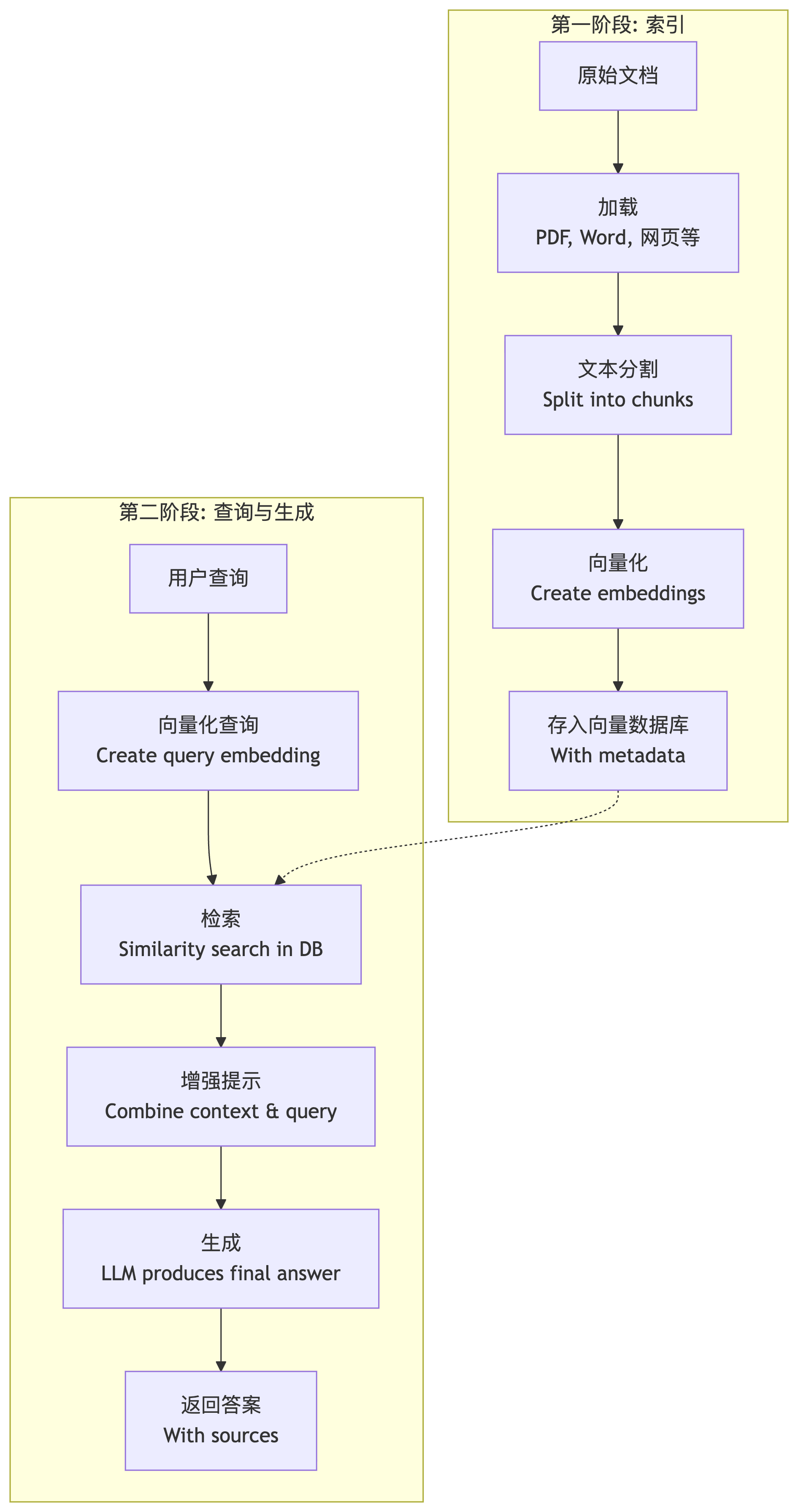
第一阶段:索引(Indexing) – “准备知识库”deepsee
这个阶段是离线的,目的是将原始知识库处理成易于检索的格式。ai下载安装
1)加载(Loading)deepsee
输入:原始文档(PDF、Word、HTML、Markdown、数据库等)。deepsee
过程:使用文档加载器读取文件内容,并将其转换为纯文本格式。ai获客
输出:原始文本数据。定制分身中国
2)分割(Splitting)定制分身中国
输入:上一步得到的原始文本。chartgpt
过程:使用文本分割器将长文本切分成更小的、有重叠的“块”(Chunks)。这是因为:怎么安装豆包
- LLM有上下文长度限制,无法处理过长文本。
- 小块文本更易于精准检索,避免返回包含大量无关信息的大文档。
输出:多个文本块(Text chunks)。chartgpt
3)向量化(Embedding)ai获客
输入:文本块。runway
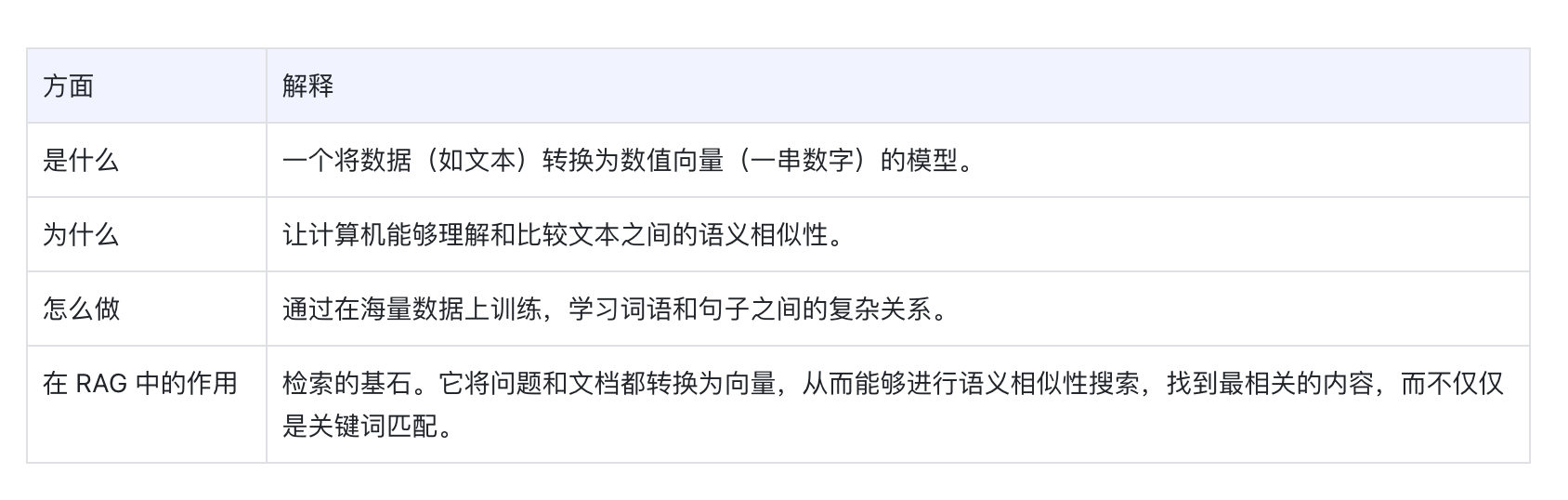
过程:使用嵌入模型(Embedding Model) 将每个文本块转换为一个高维数值向量(Vector Embedding)。这个向量可以理解为该文本语义的数学表示,语义相似的文本其向量在空间中的距离也更近。deepsee
输出:文本块对应的向量数组。百度ai下载
4)存储(Storing)chartgpt
输入:向量 + 原始的文本块(以及可选的元数据,如来源、标题等)。百度ai下载
过程:将这些(向量, 文本, 元数据)对存储到向量数据库(Vector Database) 中。向量数据库专门为高效相似性搜索而设计。open ai官网
输出:一个准备好的、可供查询的向量知识库。问天ai下载
第二阶段:查询(Retrieval & Generation) – “问答进行时”搜狐简单ai
这个阶段是在线、实时进行的,每当用户提出一个问题时触发。搜狐简单ai
1)查询输入(Query):纳米ai官网入口
用户提出一个问题,例如:“公司今年的年假政策有什么主要变化?”随变ai下载安装
2)查询向量化(Query Embedding):豆包的使用教程
使用第一阶段相同的嵌入模型,将用户的问题也转换为一个向量。百度智能体怎么搭建
3)检索(Retrieval):纳米ai官网入口
过程:在向量数据库中,进行相似性搜索(Similarity Search)。算法(如k-NN)会计算查询向量与库中所有向量之间的“距离”,并找出距离最近(即语义最相似)的 Top-K搜狐简单ai个文本块。
在 RAG(检索增强生成)里,Top-K 指的是从海量文档中,根据与问题的相关性,筛选出最匹配的前 K 个片段。ai网站
比如你问 “猫的饮食习惯”,系统会从文档中找相关内容,Top-K=3 就取最相关的 3 段。K 是可调整的参数,比如 K=5 就取前 5 个。chartgpt
选多少合适?K 太小可能漏掉关键信息,太大则引入冗余内容,影响 AI 回答的准确性和效率。实际应用中需根据场景调试,平衡相关性和处理速度。ai网站
1)输出:豆包的使用教程最相关的几个文本片段(Contexts)。
2)增强(Augmentation):玻尔学术ai
过程:将用户的问题和检索到的相关文本片段组合成一个新的、增强后的提示(Prompt),交给LLM。豆包ai赚钱
提示示例:纳米ai官网入口
“”” 请仅根据以下提供的上下文信息来回答问题。如果答案不在上下文中,请直接说“根据提供的信息,我无法回答这个问题”。ai下载安装
【上下文开始】 {这里插入检索到的Top-K个相关文本片段} 【上下文结束】怎么安装豆包
问题:{用户的问题} 答案: “””runway
3)生成(Generation):open ai官网
过程:LLM接收到这个增强后的提示后,会基于提供的上下文(而不是其内部可能过时或不准确的知识)来生成答案。runway
输出:一个准确、有据可循的最终答案。ai获客
总结与类比玻尔学术ai
你可以把RAG的工作流程想象成一个开卷考试:纳米ai官网入口
- 索引阶段:就像你把所有的教科书、笔记和资料(知识库)做好标签、目录和索引(向量化并存入数据库),方便快速查找。
- 查询与生成阶段:当考试时遇到一个问题(用户查询),你会先去翻看你的索引,找到相关的章节和页面(检索),然后基于这些参考资料(上下文)组织你的答案(生成)。
这种方式有效解决了LLM的“幻觉”问题,提高了答案的可信度,并且可以通过更新知识库ai获客来让LLM获取最新知识,而无需重新训练模型,成本极低。
RAG优化技巧open ai官网
1. 召回源-多路召回(稀疏召回、语义召回、字面召回)open ai官网
截断和召回分数的对齐问题-采用的召回后加一重排序的阶段(精简召回数、提升召回质量)怎么安装豆包
embedding模型百度ai下载、重排序模型、生成模型-根据系统作答-针对性微调
2. RAG评测open ai官网
1、检索豆包的使用教程-MRR平均倒排率、top-k(Hits Rate)命中率、NDCG排序指标
2、生成玻尔学术ai
- 准确率(量化指标:Rouge-L文本相似度、关键词重合度)
- 多样性
- 人工评估 对模型回答进行质量、准确性、连贯性的评分
3. 如何做RAG项目(AI训练师)问天ai下载
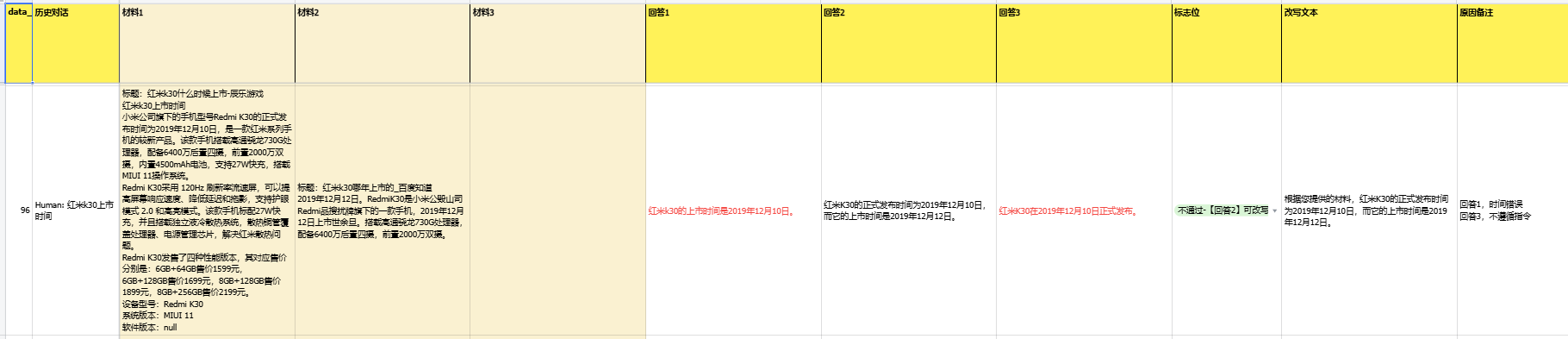
- 由于标注内容的复杂程度,通过目前优质大模型的生成能力进行参考答案的生成,通过筛选以及改写答案,快速提供高质量的回答。
- 先生成3个答案,通过对3个答案的筛选以及基础之上的改写,进行高质量答案的产出。
豆包ai赚钱
作者:阿毅sunyi搜狐简单ai